input = read_line(); /* Get input */ phase_1(input); /* Run the phase */ phase_defused(); /* Drat! They figured it out! * Let me know how they did it. */ printf("Phase 1 defused. How about the next one?\n");
CMP subtracts the operands and sets the flags. Namely, it sets the zero flag(ZF) if the difference is zero (operands are equal).
TEST sets the zero flag, ZF, when the result of the AND operation is zero. If two operands are equal, their bitwise AND is zero when both are zero. TEST also sets the sign flag, SF, when the most significant bit is set in the result, and the parity flag, PF, when the number of set bits is even.
JE [Jump if Equals] tests the zero flag and jumps if the flag is set. JE is an alias of JZ
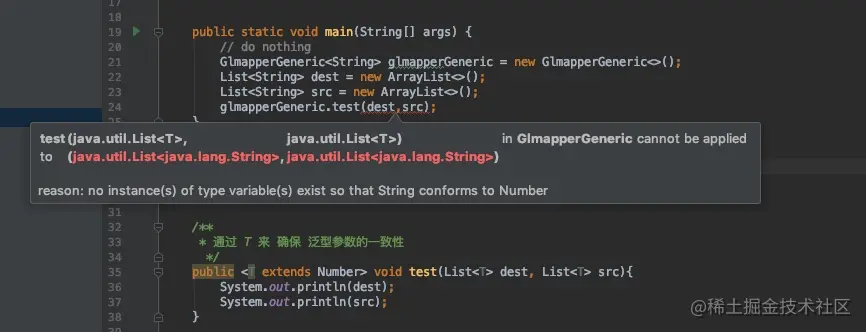
T 是一个 确定的 类型,通常用于泛型类和泛型方法的定义,?是一个 不确定 的类型,通常用于泛型方法的调用代码和形参,不能用于定义类和泛型方法。
区别1:通过 T 来 确保 泛型参数的一致性
1 2 3 4 5 6 7
// 通过 T 来 确保 泛型参数的一致性 public <T extends Number> void test(List<T> dest, List<T> src) //通配符是 不确定的,所以这个方法不能保证两个 List 具有相同的元素类型 publicvoid test(List<? extends Number> dest, List<? extends Number> src)
像下面的代码中,约定的 T 是 Number 的子类才可以,但是申明时是用的 String ,所以就会飘红报错。
不能保证两个 List 具有相同的元素类型的情况
1 2 3 4
GlmapperGeneric<String> glmapperGeneric = new GlmapperGeneric<>(); List<String> dest = new ArrayList<>(); List<Number> src = new ArrayList<>(); glmapperGeneric.testNon(dest,src);
上面的代码在编译器并不会报错,但是当进入到 testNon 方法内部操作时(比如赋值),对于 dest 和 src 而言,就还是需要进行类型转换。
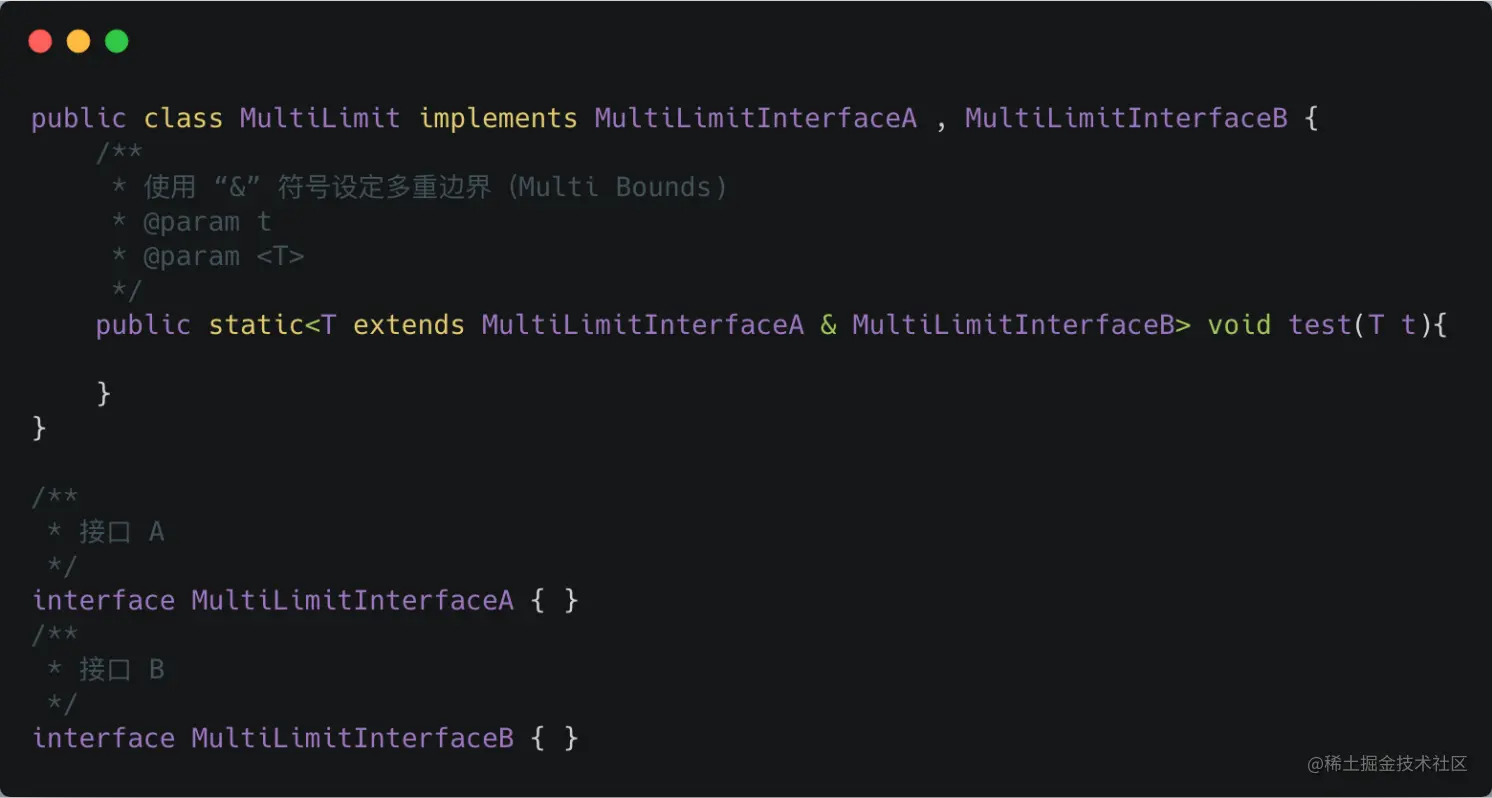
区别2:类型参数可以多重限定而通配符不行
使用 & 符号设定多重边界(Multi Bounds),指定泛型类型 T 必须是 MultiLimitInterfaceA 和 MultiLimitInterfaceB 的共有子类型,此时变量 t 就具有了所有限定的方法和属性。对于通配符来说,因为它不是一个确定的类型,所以不能进行多重限定。
Two's complement is executed by 1) inverting (i.e. flipping) all bits, then 2) adding a place value of 1 to the inverted number. For example, say the number +6 is of interest. +6 in binary is 0110 (the leftmost MSB is needed for the sign; positive 6 is not 110 because it would be interpreted as -2). Step one is to flip all bits, yielding 1001. Step two is to add the place value one to the flipped number, which yields 1010. To verify that 1010 indeed has a value of -6, remember that two's complement makes the most significant bit represent a negative place value, then add the place values: 1010 = 1(-23)+0(22)+1(21)+0(20) = 1(-8) + 0 + 1(2) + 0 = -6.