Elasticsearch学习(一)
一、什么是Elasticsearch
Elasticsearch是基于 Lucene 的 Restful 的分布式实时全文搜索引擎,每个字段都被索引并可被搜索,可以快速存储、搜索、分析海量的数据。
全文检索是指对每一个词建立一个索引,指明该词在文章中出现的次数和位置。当查询时,根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式。这个过程类似于通过字典中的检索字表查字的过程。
二、结构化数据和非结构化数据
结构化数据
结构化数据是在放入数据存储之前已经预定义并格式化为集合结构的数据,这通常被称为写时模式。 结构化数据的最佳示例是关系数据库:数据已被格式化为精确定义的字段,例如信用卡号或地址,以便使用 SQL 轻松查询。
非结构化数据
非结构化数据是以其初始格式存储的数据,在使用之前不会对其进行处理,这称为读取模式。 它有多种文件格式,如媒体、图像、音频、传感器数据、文本数据等。
三、为什么不直接使用Lucene?
Lucene可以说是当下最先进、高性能、全功能的搜索引擎库。但是 Lucene 仅仅只是一个库并且Lucene 非常复杂。
Elasticsearch通过隐藏Lucene的复杂性,取而代之的提供一套简单一致的RESTful API。
Elasticsearch不仅仅是Lucene,并且也不仅仅只是一个全文搜索引擎。它可以被下面这样准确的形容:
四、为什么不用MySQL模糊查询
1 | select * from user where name like '%yuanli%' |
这不就可以把yuanli相关的内容搜索出来了吗?
的确,这样做的确可以。但是要明白的是:name like %yuanli%这类的查询是不走索引的,不走索引意味着:只要你的数据库的量很大(1亿条),你的查询肯定会是秒级别的。
而且,即便给你从数据库根据模糊匹配查出相应的记录了,那往往会返回大量的数据给你,往往你需要的数据量并没有这么多,可能50条记录就足够了。
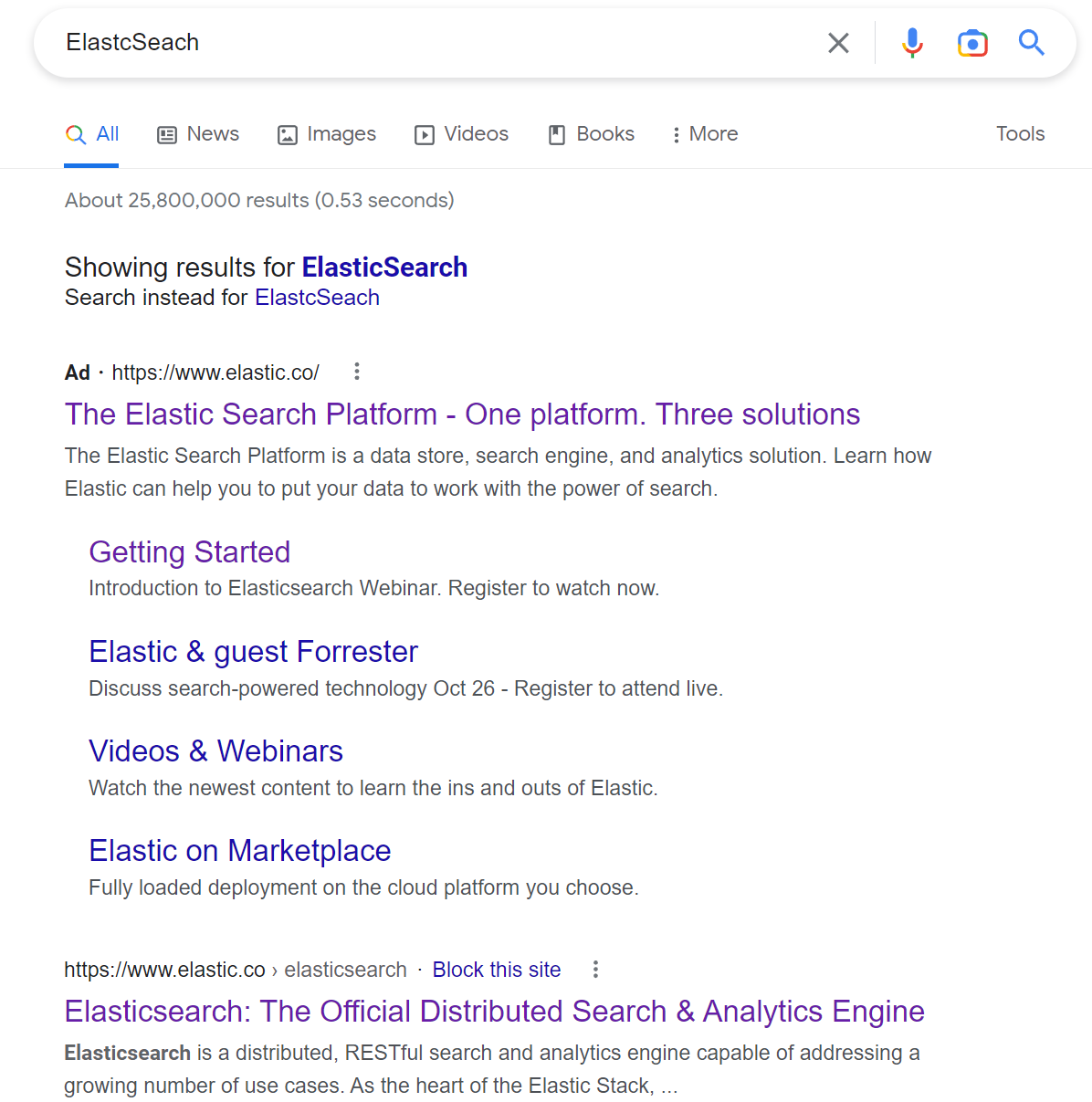
还有一个就是:用户输入的内容往往并没有这么的精确,比如我从Google输入ElastcSeach(打错字),但是Google还是能估算我想输入的是Elasticsearch
而Elasticsearch是专门做搜索的,就是为了解决上面所讲的问题而生的,换句话说:
- Elasticsearch对模糊搜索非常擅长(搜索速度很快)
- 从Elasticsearch搜索到的数据可以根据评分过滤掉大部分的,只要返回评分高的给用户就好了(原生就支持排序)
- 没有那么准确的关键字也能搜出相关的结果(能匹配有相关性的记录)
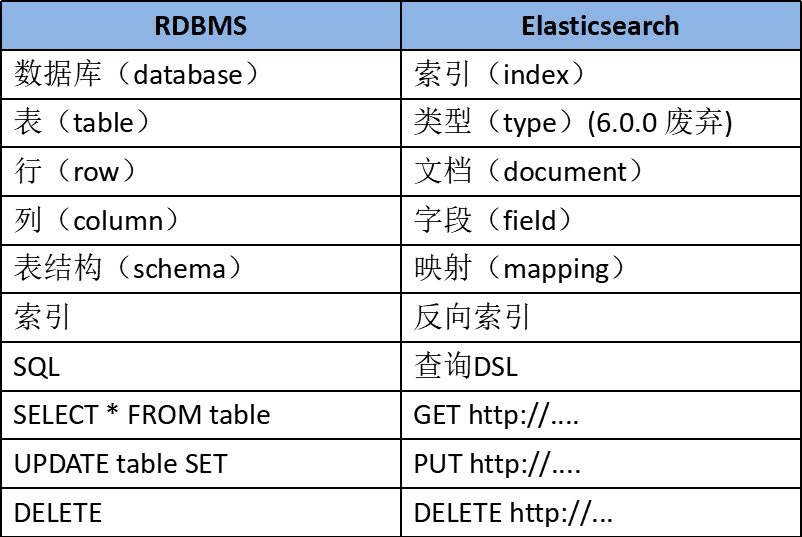
五、Elasticsearch的基础概念
Elasticsearch 是面向文档型数据库,一条数据在这里就是一个文档。
- Near Realtime(NRT) 近实时。数据提交索引后,立马就可以搜索到。
- Cluster 集群,一个集群由一个唯一的名字标识,默认为“elasticsearch”。集群名称非常重要,具有相同集群名的节点才会组成一个集群。集群名称可以在配置文件中指定。
- Node 节点:存储集群的数据,参与集群的索引和搜索功能。像集群有名字,节点也有自己的名称,默认在启动时会以一个随机的UUID的前七个字符作为节点的名字,你可以为其指定任意的名字。通过集群名在网络中发现同伴组成集群。一个节点也可是集群。
- Index 索引: 一个索引是一个文档的集合(等同于solr中的集合)。每个索引有唯一的名字,通过这个名字来操作它。一个集群中可以有任意多个索引。
Type 类型:指在一个索引中,可以索引不同类型的文档,如用户数据、博客数据。从6.0.0 版本起已废弃,一个索引中只存放一类数据。- Document 文档:被索引的一条数据,索引的基本信息单元,以JSON格式来表示。
- Shard 分片:在创建一个索引时可以指定分成多少个分片来存储。每个分片本身也是一个功能完善且独立的“索引”,可以被放置在集群的任意节点上。
- Replication 备份: 一个分片可以有多个备份(副本)